Si estás leyendo esto seguro que ya conoces el servicio Latch, ya tienes instalada la aplicación en tu móvil, has estado latcheando en Nevele Bank (tu fake bank y cada día el de más gente) probando el servicio, jugueteando con la granularidad de las operaciones e incluso lo has implantado en los sitios y servicios que administras, y por lo tanto ya conoces la interface de configuración de la web de Latch. En este artículo vamos a profundizar un poquito más en las Operaciones Latch y el jugo que podemos sacarles. Para ello vamos a utilizar el plugin de Latch para WordPress y su correspondiente SDK en PHP, aunque puedes aplicar esto en cualquier implementación. Además, ya tenemos algo de información de qué es lo que hace el plugin de Latch para WordPress documentado.
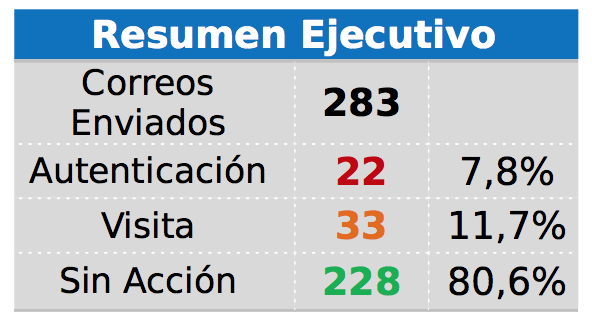
Las Operaciones Latch están pensadas para granular un servicio en "subtareas" que pueden ser validadas mediante Latch, restringiendo así el acceso a parte de las funcionalidades de un servicio. La respuesta que obtenemos a una petición de estado de una Operación sigue la misma estructura en JSON que una petición de estado para una Aplicación. Como esa estructura es común independientemente del "tipo" de consulta que le hagamos a Latch (estado de una aplicación o estado de una operación), la interpretación que hagamos de esa respuesta depende de nosotros... Veámoslo con un ejemplo:
Entorno de Partida:
En una ONG en la que colaboro desde hace poquito, tienen una página web (www.ejemplo.es) en WordPress con su propia base de datos. Al mismo tiempo existen tres subdominios (sub1.ejemplo.es, sub2.ejemplo.es y sub3.ejemplo.es) que tienen cada uno su propia instalación de WordPress y su propia Base de datos. Al ser todos independientes, necesito dar de alta una Aplicación distinta en el servicio Latch para gestionar el acceso a cada una. Esto producirá un Latch distinto para cada dominio en la pantalla principal de la aplicación Latch del móvil del usuario, junto con el resto de Latches de los distintos sitios dónde se haya dado de alta (Movistar, Tuenti, Shodan, etc... o tu propio Windows o Linux)
¿Y cómo puedo hacer que en la pantalla principal del móvil del usuario se muestre un solo Latch para mi dominio principal y que los subdominios funciones como Operaciones?
Fácil... Dándole otro significado a lo que es una Operación en Latch: En lugar de usarla para validar una funcionalidad, la vamos a usar para validar el acceso principal a la aplicación... o lo que es lo mismo, le vamos a dar el mismo valor que a una Aplicación.
De cara al usuario queremos cambiar cómo le aparecen los Latches de:
A algo del estilo:
El plugin de WordPress seguirá el mismo procesamiento para todo (parear usuario, desparear usuario, OTP, etc) excepto cuando de una tarea de autenticación se trate. En este caso haremos que WordPress consulte el estado de una Operación Latch en lugar de consultar el de una Aplicación. Al seguir utilizando el "Application ID" para el resto de tareas, podremos seguir utilizando el resto de funcionalidades del plugin con normalidad. Si configuramos el "Operation ID" en el campo reservado al "Application ID" nos fallará porque estaremos haciendo una consulta de tipo Aplicación con un ID que no es válido para ello.
¿Y qué necesito para hacer esto?
También es fácil.. Necesitaremos un poquito (sólo un poquito...) de RTFM de:
Las Operaciones Latch están pensadas para granular un servicio en "subtareas" que pueden ser validadas mediante Latch, restringiendo así el acceso a parte de las funcionalidades de un servicio. La respuesta que obtenemos a una petición de estado de una Operación sigue la misma estructura en JSON que una petición de estado para una Aplicación. Como esa estructura es común independientemente del "tipo" de consulta que le hagamos a Latch (estado de una aplicación o estado de una operación), la interpretación que hagamos de esa respuesta depende de nosotros... Veámoslo con un ejemplo:
Entorno de Partida:
En una ONG en la que colaboro desde hace poquito, tienen una página web (www.ejemplo.es) en WordPress con su propia base de datos. Al mismo tiempo existen tres subdominios (sub1.ejemplo.es, sub2.ejemplo.es y sub3.ejemplo.es) que tienen cada uno su propia instalación de WordPress y su propia Base de datos. Al ser todos independientes, necesito dar de alta una Aplicación distinta en el servicio Latch para gestionar el acceso a cada una. Esto producirá un Latch distinto para cada dominio en la pantalla principal de la aplicación Latch del móvil del usuario, junto con el resto de Latches de los distintos sitios dónde se haya dado de alta (Movistar, Tuenti, Shodan, etc... o tu propio Windows o Linux)
¿Y cómo puedo hacer que en la pantalla principal del móvil del usuario se muestre un solo Latch para mi dominio principal y que los subdominios funciones como Operaciones?
Fácil... Dándole otro significado a lo que es una Operación en Latch: En lugar de usarla para validar una funcionalidad, la vamos a usar para validar el acceso principal a la aplicación... o lo que es lo mismo, le vamos a dar el mismo valor que a una Aplicación.
De cara al usuario queremos cambiar cómo le aparecen los Latches de:
 |
| Figura 1: Ejemplo de varios WordPress aislados |
A algo del estilo:
 |
| Figura 2: Ejemplo de agrupación en suboperaciones |
El plugin de WordPress seguirá el mismo procesamiento para todo (parear usuario, desparear usuario, OTP, etc) excepto cuando de una tarea de autenticación se trate. En este caso haremos que WordPress consulte el estado de una Operación Latch en lugar de consultar el de una Aplicación. Al seguir utilizando el "Application ID" para el resto de tareas, podremos seguir utilizando el resto de funcionalidades del plugin con normalidad. Si configuramos el "Operation ID" en el campo reservado al "Application ID" nos fallará porque estaremos haciendo una consulta de tipo Aplicación con un ID que no es válido para ello.
¿Y qué necesito para hacer esto?
También es fácil.. Necesitaremos un poquito (sólo un poquito...) de RTFM de:
- La API de Latch (disponible en el Developer Area de la web de Latch) para tener una idea de cómo funciona
- La API de WordPress, concretamente las funciones dedicadas a los "Settings"
- Una pequeña idea del SDK de Latch para PHP incluido en el plugin de WordPress
- Leche
- Arina
- Huevos
- Definimos un nuevo campo para el "Operation ID"
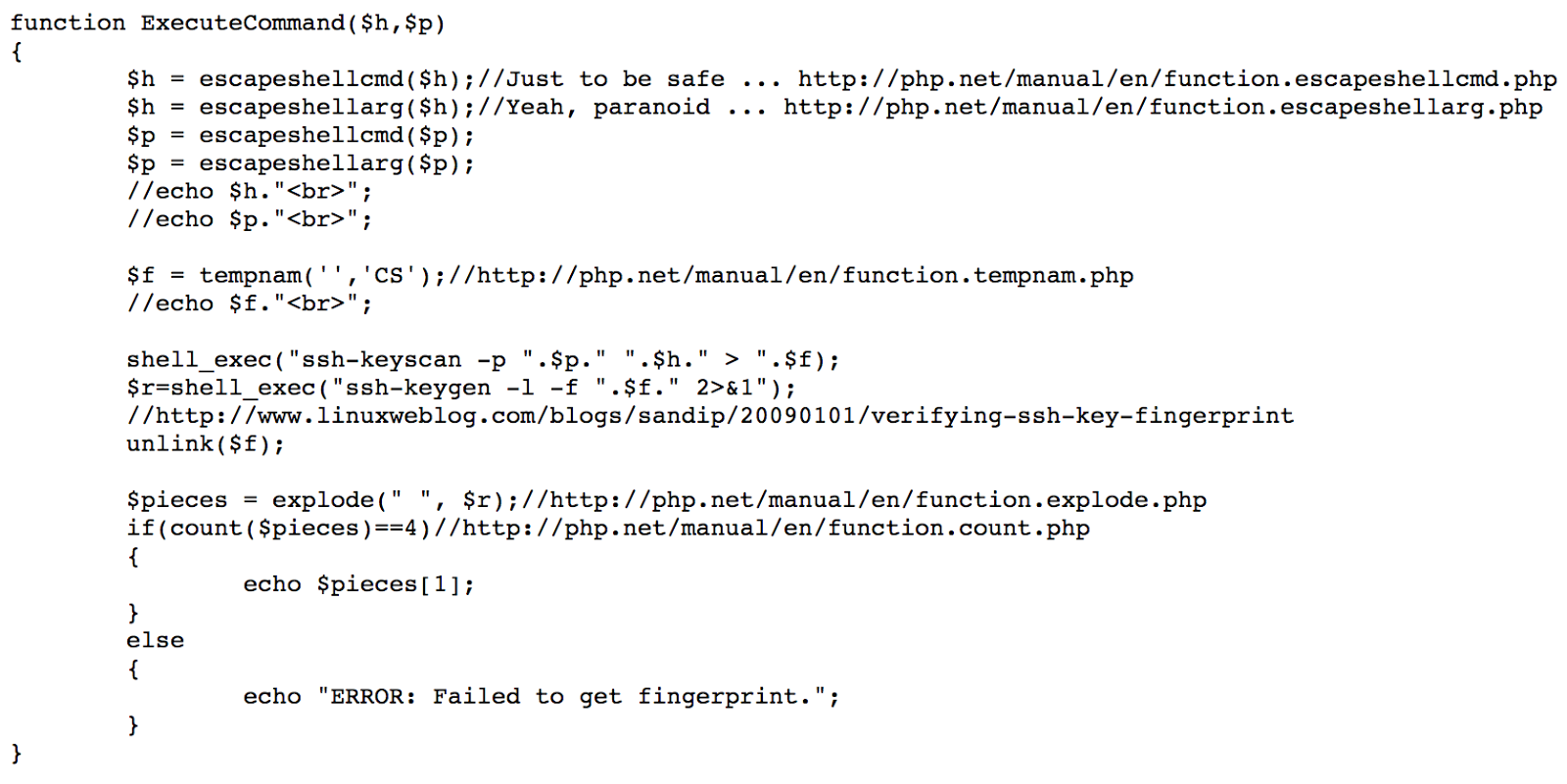
- Lo primero es poner un campo en el formulario de la configuración general de Latch en WordPress para que almacene en la base de datos el ID de Operación que obtendremos de la web de Latch. Para ello modificaremos el fichero latch.php del plugin de WordPress incluyendo las siguientes líneas a la función action_admin_init():
function action_admin_init() {add_settings_section('latch_settings', 'Global settings', array('latch', 'latch_settings_content'), 'latch_settings');add_settings_field('latch_appId', 'Application ID', array('latch', 'latch_settings_appId'), 'latch_settings', 'latch_settings');add_settings_field('latch_appSecret', 'Secret key', array('latch', 'latch_settings_appSecret'), 'latch_settings', 'latch_settings');add_settings_field('latch_host', 'API URL', array('latch', 'latch_settings_host'), 'latch_settings', 'latch_settings');/* OTt: Add a new record to store the Operation ID (if needed) */ add_settings_field('latch_opId', 'Operation ID', array('latch', 'latch_settings_opId'), 'latch_settings', 'latch_settings'); register_setting('latch_settings', 'latch_appId', array('latch', 'latch_validate_appId')); register_setting('latch_settings', 'latch_appSecret', array('latch', 'latch_validate_appSecret')); register_setting('latch_settings', 'latch_host', array('latch', 'latch_validate_host'));- /* OPT: Register the record to be printed in the configuration page of Latch */
register_setting('latch_settings', 'latch_opId', array('latch', 'latch_validate_opId'));
}
Esta función es asociada al nuevo campo "Operation ID" en el paso anterior (en la llamada a add_settings_field()). Cuando WordPress tenga que imprimir la página de configuración general de Latch, llamará a todas las funciones asociadas a cada campo de la configuración para que se impriman dentro de un formulario. Esta nueva función es un clon de la función latch_settings_appSecret(), cambiando los nombres de los campos del formulario. La incluiremos en el mismo fichero que antes (latch.php) y por seguir un orden, podéis hacerlo debajo de la función latch_settings_appSecret():
/* OPT Bloq: Function to print the new Operation ID field in the configuration form */function latch_settings_opId() {$opId = esc_attr(get_option('latch_opId'));echo '<input id="latch_opId" maxlength="20" name="latch_opId" size="45" type="text" value="' . $opId . '" />';
} /* END OPT Bloq */
Cuando se realice un submit del formulario de la configuración general de Latch, se utilizará una función para la validación de cada campo del mismo. Esta función también se ha definido en el primer paso, y la función que hemos copiado es latch_validate_appId():
/* OPT Bloq: Function to validate the new Operation ID field */function latch_validate_opId($opId){ if (!empty($opId) && strlen($opId) != 20) { add_settings_error('latch_invalid_opId', 'latch_invalid_opId', __('Invalid operation ID')); return ''; } else { return $opId; } } /* END OPT Bloq */ En este punto ya hemos conseguido que se guarde nuestro nuevo campo "Operation ID" en la base de datos de WordPress. ¿Hasta aquí bien? ¿Alguna pregunta? ¿Bien?... OK, seguimos:
La función encargada de la autenticación también se encuentra en el fichero latch.php y se llama filter_authenticate(). Es la encargada de comprobar el estado del latch para el "Application ID" que se haya configurado. Nosotros la vamos a modificar para que, en caso de que haya definido un "Operation ID" utilice este en lugar del de la Aplicación. Lo primero es definir una nueva variable ($opId) dentro de esta función para almacenar nuestro "Operation ID" desde la Base de datos. Lo hacemos incluyendo la siguiente línea al comienzo de la función:
function filter_authenticate($user, $username = '', $password = '') {El plugin instancia un objeto de la clase LatchSDK() y llama al método status()para obtener el estado del Latch del usuario en cuestión. Si buscamos las siguientes líneas podemos verlo más claramente:if (!is_a($user, 'WP_User')){
return $user;
}else{
$appId = get_option('latch_appId');/* OPT: Get The new Operation ID field from the database */$opId = get_option('latch_opId');$appSecret = get_option('latch_appSecret');$host = get_option('latch_host');...
La clase LatchSDK() dispone de otro método llamado operationStatus() para la comprobación del estado de una Operación. Vamos a modificar las líneas anteriores para discriminar en función de nuestra configuración (de si hemos configurado un "Operation ID"):$api = new LatchSDK($appId, $appSecret);$statusResponse = $api->status($latch_accountId);
$api = new LatchSDK($appId, $appSecret);/* OPT Bloq: IF $opId is NOT empty, I will use the operationStatus() method from SDK (instead status() method) and I asign the $opId value to $appId to reuse the subsequent code */ //$statusResponse = $api->status($latch_accountId);if (empty($opId)){ $statusResponse = $api->status($latch_accountId); }else{$appId = $opId;$statusResponse = $api->operationStatus($latch_accountId, $appId);}
/* END OPT Bloq *//* END OPT Bloq */
Podemos observar que además de cambiar el método utilizado para solicitar el estado al servicio Latch, machacamos la variable correspondiente al "Application ID" ($appId) con el valor de nuestro nuevo campo "Operation ID" ($opId). Como ya hemos comentado antes, la estructura de datos en JSON con la que nos responde Latch es la misma independientemente de que se lo pidamos para un "Application ID" o para un "Operation ID", por lo que machacando el ID de Aplicación con el ID de Operación, el resto del código nos servirá para consultar el valor de la Operación ;)
if (defined('WP_UNINSTALL_PLUGIN')){delete_option('latch_appId');delete_option('latch_appSecret');delete_option('latch_host');
/* OPT: Delete the new latch_opId field */ delete_option('latch_opId');$all_user_ids = get_users('fields=ID');foreach ($all_user_ids as $user_id){delete_user_meta($user_id, 'latch_id');delete_user_meta($user_id, 'latch_two_factor');}
}
Latch moOola... tenemos un montón de posibilidades. Con esto conseguimos agrupar aplicaciones independientes dentro de un "Latch Raíz" utilizando sus Operaciones como referencia para el login sin necesidad de copiar registros de una base de datos a otra, ya que el proceso de pareado seguirá utilizando el "Application ID" en lugar del "Operation ID". Si queremos utilizar el "Latch Raíz" para el login, podemos hacerlo dejando vacío el nuevo campo para la Operación.
Esto mismo podemos utilizarlo en distintas situaciones:
- Telefónica puede implementar un Latch para movistar.es, otro para telefónica.es y otro para terra.es, haciendo que el usuario tenga tres "Latches Raíz" en la página principal de la aplicación de su móvil, o puede, con lo que hemos explicado aquí, tener un único "Latch Raíz" llamado Telefónica, y como operaciones de este el acceso a terra.es, a movistar.es y a telefónica.es, "enguarrando" menos la página principal de la APP del usuario y sobre todo permitiendo que el usuario cierre el acceso a TODAS esas webs desde el "Latch Raíz".
- Si gestionamos el acceso a nuestra Intranet mediante Latch, podemos agrupar las distintas aplicaciones dentro de una única Aplicación Latch. Cada vez que cerremos ese latch, estaremos cerrando el acceso a TODAS las aplicaciones
- Como la granularidad de las Operaciones es ilimitada, podemos tener un Latch general para nuestra infraestructura empresarial y como operaciones las subredes que lo componen. Como operaciones de cada subred podemos tener los equipos de dicha red, y dentro de cada equipo gestionar el acceso por SSH, HTTP, etc... O si lo preferimos lo podemos agrupar por tipos de accesos... Up to you!!
Analista de Sistemas y Seguridad en BT España